Introduction
In a recent workshop on Large Language Models (LLMs), we asked attendees which LLMs they’re using or considering for their use cases. It turns out everyone was primarily focused on open-source LLMs like Mistral 7B, Llama 2, and Falcon. This left us wondering about a recent report by Reuters on OpenAI’s growth.
The report pointed out that OpenAI’s revenue has crossed US$1.6 Billion. Assuming the majority of revenue likely comes from their public ChatGPT offering, at a US$20 monthly subscription price for access to the premium GPT-4 model, this roughly translates to 80 million users. That’s a lot of users, and, coupled with my workshop poll, it gave me an indication that there is probably room in the world for both open-source LLMs as well as closed-source models like ChatGPT-4. But as an increasing number of organizations are beginning to experiment with LLMs, choosing the right foundation model is more important than ever.
This article primarily compares and contrasts the use of OpenAI’s closed-source LLM versus open-source LLMs on relevant criteria. We’re using OpenAI as an example of a proprietary LLM due to its top-notch performance and popularity. However, similar arguments apply to other providers like Anthropic, Google Palm, and Cohere.
Tip: If you have already decided to take an open-source approach, you might find our article on choosing the right LLM for your use case to be a useful resource.
What is OpenAI?
OpenAI is a US-based research startup founded in 2015. OpenAI started as a non-profit with the goal of “safe and beneficial” artificial general intelligence (AGI). The company has since transitioned to a “capped” for-profit company focusing mainly on developing LLMs and Large Multimodal Models (LMMs). The release of Dall-E and ChatGPT made OpenAI a worldwide name and set the stage for wider interest in LLMs and Generative AI (GenAI).
OpenAI developed GPT-4 (Generative Pre-trained Transformer 4), the LLM behind premium ChatGPT consisting of 1.76T parameters, trained on a wide variety of internet data. Its ability to understand and respond to general user inputs with nuanced language makes it a powerful tool for a new generation of chatbots, virtual assistants, and various customer service applications. Additionally, OpenAI claims to have fine-tuned the models behind ChatGPT to balance safety and usefulness, addressing concerns related to inappropriate or biased content generation.
Open-source LLMs
Open-source LLMs have been in the making for quite some time. However, these models initially performed poorly compared to proprietary models like GPT. Llama 1 was the first high-quality, open-source LLM released in Feb 2023. Since then, we’ve seen a variety of open-source LLMs coming to the market such as Mistral 7B, Falcon 180, variations of Bert, etc.
Open-source LLMs have gained popularity due to enhanced data security, privacy, and customization opportunities. Recent evaluations of LLMs show open-source models reaching a level of quality and performance closer to proprietary models on various benchmarks. Thus, open-source LLMs present a credible alternative to OpenAI (or other such closed-source models) for building a new generation of products and services.
Successfully deploying an LLM-based service in production is a process that entails many phases, typically referred to as LLMOps. Based on the experiences of our customers, we assembled the following criteria for choosing open-source vs. closed-source LLMs for implementation: development and customization needs, performance and reliability, security, and costs.
Development and customization
Organizations want to build and deploy LLMs for their use case and within their business context. The problem is that LLMs pre-trained over a vast quantity of internet data generally don’t work out of the box for company-specific use cases. They lack the business and application context, causing their responses to, at best, lack depth or miss important details, and at worst, hallucinate and make things up. Thus, most LLMs need to be customized and require additional development (e.g. fine-tuning, RAG, prompt engineering, etc.) to work properly.
With GPT-4, OpenAI offers an extremely powerful LLM out of the box as an API service. This enables developers to easily integrate and build their applications on top of an OpenAI model. Thus, development is primarily focused on better prompting the model, referred to as prompt engineering, and refining the user experience. Since the model runs on OpenAI servers as a scalable live service, no AI infrastructure management is required. Additionally, the development team doesn’t require an extensive specialization in LLMs and can therefore build LLM-based applications with limited expertise. However, due to the closed-source nature of GPT-4, you have limited customization possibilities or details about the model itself. If OpenAI changes their model, your prompt engineering, for example, might need to be adjusted.
On the other hand, open-source models offer greater control over development and customization. Teams can fine-tune, retrain, modify, and host these models to fit their needs. Unlike with proprietary models like GPT-4, teams can have more insight into the inner functioning of open-source models, which helps researchers and data scientists to build more tailored solutions.
If you’re building a niche LLM-based application with an in-depth understanding of a proprietary dataset and have in-house data science capabilities, an open-source pre-trained LLM is generally recommended. However, if your use case is primarily built around using general/public data and the focus is more on go-to-market speed, OpenAI’s GPT-4 is an easier option for building LLM applications.
Performance & reliability
Measuring the performance and reliability of pre-trained LLMs is a challenging task. Often, the questions or tasks assigned to LLMs can be open-ended, which makes it difficult to evaluate the response quality. Factors such as use case type, output accuracy, model size, inference speed, required computational resources, and data privacy make it even more difficult to properly benchmark LLMs or even choose the right benchmark. Performance of the same LLM can vary depending on the task and chosen benchmark. Given a variety of LLM applications like chatbots, summarizing text, searching and retrieving information, code generation, and sentiment analysis, choosing the right approach to evaluating an application can make a difference.
Here are some popular benchmarks that you can consider for your project:
- MMLU (k-shot): Massive Multi-task Language Understanding (MMLU) is an evaluation benchmark designed to test the performance of a language model’s accuracy on multiple tasks and multiple domains. This comprehensive benchmark consists of 57 tasks across a variety of topics such as elementary math, US history, law, computer science, and more. The benchmark dataset consists of 15908 questions, split into a few-shot development set, a validation set, and a test set. You can check the ranking of popular foundation models like GPT-4, Llama 2, Gemini, Palm 2, and Mistral 7B on this MMLU leaderboard. This benchmark primarily tests the breadth and granularity of an LLM’s knowledge along with its problem-solving ability, making it relevant for use cases that require a generalization. Models can be analyzed based on coherence, relevance, clarity, and detail.
- ARC benchmark: The AI2 Reasoning Challenge (ARC) benchmark evaluates an LLM’s knowledge and reasoning capabilities. The ARC dataset consists of 7787 multiple-choice questions and is split into a Challenge Set and an Easy set. If your application requires higher reasoning capabilities like humans, this benchmark should be considered. ARC also has its own leaderboard.
- TriviaQA: this benchmark measures the truthfulness of a language model when answering questions. The questions are designed in such a way that even humans might give wrong answers based on their beliefs and biases. To perform well, the model must avoid false answers by not copying what humans would usually answer. It roughly has 650K question-answer-evidence triples. It tests reading comprehension and is useful for applications requiring interpretation and summarization.
- MT Bench: a curated set of questions designed to assess conversation flow and instruction following the capabilities of the LLM. 80 high-quality question datasets spread across 8 primary categories measure how an LLM responds to complex questions and logical flow.
Besides these, there are other benchmarks like: holistic evaluation of language models (HELM) for increasing transparency of models, BLEU score for comparing machine-generated text or translation to a reference text, or CoT Hub and BIG-Bench for probing capabilities of LLMs that are popular in the developer community.
To make evaluation easier, HuggingFace, a popular open-source model catalog, has created a leaderboard to track, rank, and evaluate open-source LLMs and chatbot applications. The LMSYS Chatbot Arena leaderboard specifically compares OpenAI’s GPT models with open-source alternatives on a set of benchmarks. OpenAI has also released its own evaluation results as seen in the image below.

Figure 1. GPT-4 evaluation.
Another aspect of benchmarking LLM performance is speed. When you pass an input to an LLM, you expect the response within a few seconds. You may wait a few minutes for a complicated question; however, the general expectation is to get a quick and correct response. Open-source tools like LLMPerf make it possible to evaluate LLM performance on criteria like: completed requests per minute, time to first token (TTFT), and end-to-end latency. Good performance along these criteria ensures that the LLM application not only provides a response but is within the expected timeline.
To summarize: data science teams need to pick evaluation metrics based on context and relevance. Whether GPT-4 or open-source LLMs, there is no benchmark metric that fits perfectly across every use case. Therefore, you might have to use more than one benchmark to ensure LLM performance and reliability.
Security
Security remains a critical concern in LLM application development. Since users might pass confidential information or share or access personally identifiable information (PII) while interacting with LLMs, many organizations are sensitive to the data control and security aspects of LLM deployment. Other security concerns include: data leakages, modifying LLM behavior through malicious prompt injection, insecure plugins, etc.
Given these risks, open-source models provide a path to designing and experimenting with LLMs securely. An organization can host open-source LLMs locally or in their private environment without any internet connection and without passing data to external servers. This gives more control and a secure environment to train LLMs without the risk of security incidents.
On the other hand, OpenAI models are available as API services. This means you need to transfer data or query models from their cloud servers. While OpenAI has released enterprise versions of GPT models, not all users are convinced or comfortable with sharing confidential information with third parties. Even though OpenAI announced more data controls and not use data from users to train their LLMs, concerns remain about sending data to OpenAI servers. OpenAI has been particularly ambiguous about data handling, and not releasing their training datasets creates an image of secrecy which makes some users uncomfortable. In any case, sending confidential data to external services exposes organizations to a variety of risks.
Seen in the context of cloud sovereignty and the American CLOUD Act, companies have grown conscious of securing and managing their data to be compliant with their respective jurisdictions. This applies to LLM application development and security too. Thus, for industries dealing with critical and sensitive data, such as defense, and healthcare, it seems relevant to choose open-source LLMs to build their applications.
If you would like to learn more about LLM security challenges, the Open Web Application Security Project (OWASP) guide is a great resource.
Costs
As the saying goes, there’s no such thing as a free lunch. Whether you’re using open source or OpenAI, building and running AI-based applications may require a significant investment. According to a Lamba Labs analysis, each training run for OpenAI costs around US$5M. Towards Data Science estimates OpenAI to be using more than 30K GPUs to power and run its popular ChatGPT application. Given the current technological maturity and evolving landscape, an LLM project would require sustained investment. The open-source alternatives may seem cheaper but they come with their own costs.
There are primarily two types of costs involved in LLM projects: project development and maintenance.
Project development
Once you have identified your LLM use case, typically you would define a development project for a Proof of Concept (POC). Within enterprises, deploying a fully functioning LLM can take 5–8 FTE encompassing roles like data scientists, DevOps engineers, data analysts, product owners, etc. After technical resources are assigned, you can start planning the project with a choice of foundational LLM.
From a cost perspective, you typically do not need to pay any license fee for open-source LLMs. If you check for LLMs with an Apache 2.0 license, you should have unrestricted use. You can take a look at our guide for choosing LLMs to make sure you pick the right model for your use case.
Then, you will need to build a flexible IT infrastructure to host the open-source LLMs and enable a data science team to test and experiment with them. Besides IT infra, you will require multiple man hours to connect different types of data sources, clean data, experiment, and fine-tune or implement your LLM application using the RAG approach. It can easily take around 4–8 months for enterprises to operationalize an open-source LLM. You can reduce this time by 90% by setting up in the cloud, but note that this will have downstream effects on maintenance costs as well as performance and data security.
For projects utilizing OpenAI models, teams can get started quickly using the OpenAI API. You do not need to build AI infrastructure. However, you will still have to pay to access the API. Figure 2 shows the cost of accessing the latest GPT-4 models through the OpenAI API. The cost is measured by the length of the text data passed to the LLM and the length of the generated response, typically in terms of token size (1K tokens is approximately equal to 750 words). During application development, retraining and testing LLMs can easily add up to thousands of dollars in costs. A rough estimation of usage costs is provided in Table 1.
Maintenance
Once the LLM has been customized to your needs, it should be deployed in production. The steps required to deploy, maintain, and manage LLMs in production are referred to as LLMOps. Maintenance is a particularly important part of the LLMOps life cycle. In fact, neglecting to take maintenance into account is one of the reasons behind why so many AI projects fail. Maintenance of LLMs requires clear ownership, processes, and computing resources.
Focusing on maintenance costs, most LLMs run on compute-intensive graphics processing units (GPUs). Getting access to the right type of GPU can be a challenge in itself. So, you have to either build infrastructure in-house or reserve GPUs for high availability. Some providers also have a pay-per-use option, but GPU availability is not guaranteed. Running smaller LLMs (7–15B parameters) can cost over US$2K per month. If you host a larger LLM (100–200B parameters) and run it continuously, that translates to US$18K monthly. And that’s just the infrastructure costs — you will also have to budget for associated costs like storage, data transfer, skilled staff, etc. This high cost can make deploying open-source LLMs prohibitive for many smaller organizations.
That being said, as the volume of workloads increases, the costs do not scale identically. In fact, running LLMs gets cheaper. It comes down to resource utilization. When running open-source models on-premise or in the cloud, you’re paying for the infrastructure rather than the model itself. Most cloud providers, such as Google, charge for GPU usage by the hour, and offer discounts for long-term commitments. Of course, rates vary depending on the provider. But with a flat monthly subscription at UbiOps, you can remain cloud vendor agnostic, allowing you to choose and connect to any public, private, or local cloud. So, for enterprises and organizations with high volumes of traffic, running and maintaining open-source LLMs becomes cost effective.
In the case of the OpenAI API route, the pricing consists of input and output tokens. In essence, you pay for the number of words that go into and come out of the model, including those from prompt engineering and RAG. In Table 1, you can see an example cost calculation with two variables: prompt/query length and requests per minute (low/high). At face value, using OpenAI API seems significantly cheaper than using open-source LLMs at lower volumes of interactions. But bear in mind that there are no economies of scale to be achieved at higher volumes. Instead the costs simply scale proportionally to the volume of tokens processed. Additionally, there is a risk of OpenAI changing its pricing plan which can affect your own budgeting.

Figure 2: Pricing for accessing GPT-4 API.
| Input text (in words) | Output text(in words) | Total monthly interactions | Total cost per month |
| 100 | 200 | 10K | $94 |
| 100 | 200 | 100K | $931 |
| 200 | 1K | 10K | $426 |
| 200 | 1K | 100K | $4256 |
Table 1: OpenAI API access cost. Assumptions: 75 words ~ 100 token; input token rate $0.01 per 1K tokens; output token rate $0.03 per 1K tokens; total cost per month = ( 1.33 * input token rate + 1.33 * output token rate ) * total monthly interactions.
To summarize, open-source LLMs require higher fixed costs to get started in comparison to GPT-4 API access. However, for high volume customer traffic, e.g., millions of user interactions every month, the cost factor will favor open-source implementation. This makes open-source LLMs better suited commercially in the long term, and OpenAI-based solutions more financially viable for startups or side projects.
It’s worth noting that, due to technological improvements, there has been a rise in smaller language models which can be hosted on cheaper IT infrastructure, driving down the running and maintenance costs for open-source LLMs. While OpenAI’s singular ambition is to develop an all-powerful AGI, the open-source community is driven by the needs of the many, which tends to boil down to practicality. Having full control over your LLM stack can help you take advantage of new technological developments and better manage the overall project costs.
Conclusion
The emergence of LLMs in the public domain has started a wide discussion on how we fundamentally engage with technology. Organizations are rethinking their products and services and exploring LLM use cases that can make them better, faster, or cheaper. Even though the technology is still in its early stages, constant experimentation is required to stay competitive and relevant. Ultimately, whichever LLM you choose to use, its benefits should outweigh the costs.
Choosing open-source vs OpenAI APIs (or other similar services from vendors like Google and AWS) depends on a variety of factors. If you work with sensitive data, have data science expertise, and budget for project implementation and maintenance, open-source LLMs are the most suitable option. Alternatively, if your use-case doesn’t involve sensitive data and are looking for a low-cost and quick solution for the short term, OpenAI API is a good option to experiment with. In other words, it comes down to how regulated your industry is, the size of your organization and its capabilities, the type of customer you serve, available budget and your competitive landscape. The technology will evolve fast in the coming years and choosing the route that gives you the most flexibility seems like the most reliable way to remain agile.
How can UbiOps help in the fast moving LLM landscape?
UbiOps provides a battle-tested MLOps platform to deploy, run, and manage AI workloads. Our core focus is to democratize AI and machine learning (ML) capabilities for organizations of all sizes and types. What does that mean? It means that every data scientist or ML engineer can deploy live models in hours instead of months and manage efficiently as a team. Our out-of-the-box AI infrastructure simplifies the myriad of IT hoops organizations need to jump through to deploy and manage their LLM or GenAI projects. WIth UbiOps, organizations drastically shorten their time-to-value for AI projects.
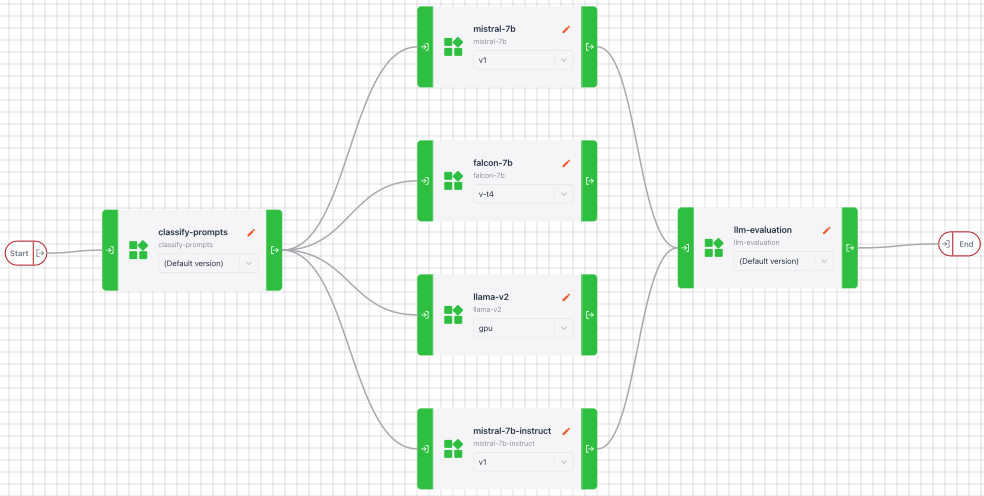
From tutorials for implementing any open-source LLMs from Hugging Face to comprehensive guides on fine-tuning, UbiOps has a rich repository of technical documentation and guides to help you deploy, manage, and scale your LLM application. We actively support implementations of open-source LLMs, and a variety of customers are building LLM applications on the UbiOps platform already. And last but not least, as the LLM landscape evolves, UbiOps pipelines allow users to plug-in multiple LLMs together, and evaluate and build on the top of the best-performing LLMs more efficiently.
UbiOps UI: picture of pipelines with multiple LLMs