Given the number of Large Language Models (LLMs) out there, finding one that meets your specific use case can be a daunting task. The field is evolving rapidly, with new models and fine-tuned versions being released every single week. It follows that any list of LLMs and how they should be applied will be rapidly outdated.
This is why it doesn’t make sense to describe each of the top LLMs and designate their strengths and weaknesses — instead, in this piece, we will try to share criteria that you can use to analyze models and check to see if they meet your needs and constraints.
This article can be used as a preliminary guide for how to evaluate a newly released model against a number of core characteristics, on which basis we will also show you how to compare models. The key characteristics of an LLM that you should consider are:
- size
- architecture type
- benchmark performance
- training processes and biases
- licensing/availability
What is the size of an LLM?
When choosing an LLM, your most important constraint is your budget. Running LLMs can be very expensive, so it is vital that you choose a model that doesn’t break the bank. To this end, the number of parameters of an LLM can give an indication of its cost.
What is the number of parameters of a model?
The number of parameters designates the number of weights and biases the model adjusts during training and uses to calculate its output. Why is the number of parameters important in a model? The number of parameters gives a rough estimate of the performance cost and the inference speed of a model. They are, for the most part, proportional to each other. This means that the more parameters a model has, the higher the cost for it to generate an output.
What is the inference speed of a model?
The inference speed of a language model designates the time a model takes to process an input. To put it simply, it is the measurement of its output speed. It should be noted that the inference speed and performance of a model is a multifaceted and complicated topic that cannot simply be gauged by the number of parameters. However, for the purposes of this article, it gives a rough estimate of a model’s potential performance. Fortunately, there are several proven methods to reduce the inference time of machine learning models.
| Model or model series | Number of parameters |
| Mistral | 7.24B, 46.7B |
| GPT-4 | 1.76T (estimated) |
| GPT-3 | 124M, 350M, 760M, 1.3B, 2.7B, 6.7B, 13B, 175B |
| LLaMA 2 | 6.74B, 70B |
| BART | 139M, 406M |
| BERT | 110M, 336M |
| Falcon | 7B, 40B |
For the record, we have dedicated guides on how to deploy Mistral, BERT, LLaMa 2 and Falcon using UbiOps.
A medium-sized model is usually under 10 billion parameters, with very cheap ones being under 1 billion. However, models under 1 billion parameters are usually pretty old or are not designed for text generation purposes. Expensive models are over 100 billion parameters, such as GPT-4 claiming to have an enormous 1.76 trillion parameters. Most model series such as LLaMa 2, Mistral, Falcon and GPT have small versions which are under 10 billion parameters and larger versions which are between 10 and 100 billion parameters.
What are the different types of LLMs?
Broadly, all transformer-based LLMs can be split into three categories depending on their architecture: encoder-only, encoder-decoder and decoder-only. The category it belongs to helps determine what the model was designed for and its text generation performance.
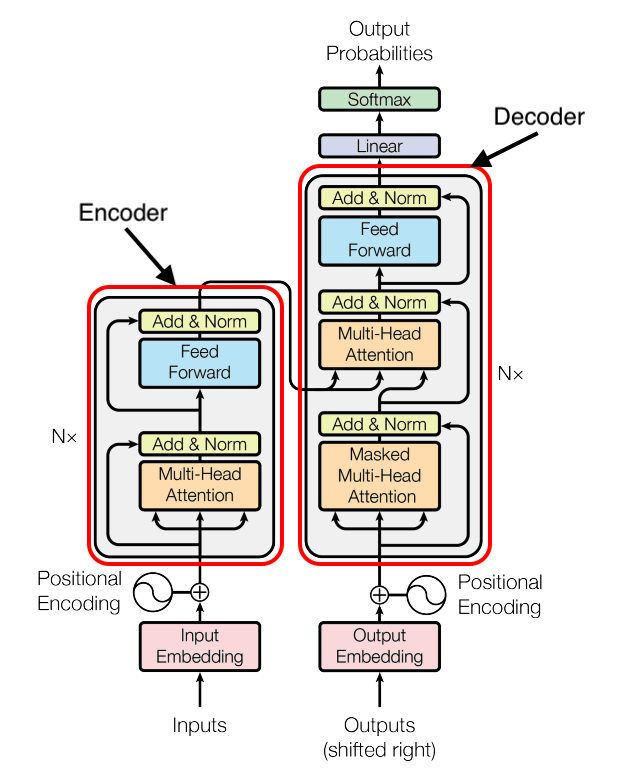
Source: Attention Is All You Need
What is an encoder-only model?
Encoder-only models only use an encoder, which encodes and classifies input text. Encoder-only models are useful for placing text into a defined category. BERT, the most prominent encoder-only model, was trained as a masked language model (MLM) and for next sentence prediction (NSP). Both of these usage types require identifying core elements in a sentence.
What is an encoder-decoder model?
Encoder-decoder models first encode the input text (like encoder-only models) and then generate or decode a response based on the now encoded inputs. BART is an example of an encoder-decoder model architecture. Encoder-decoder models can be used both for text generation and text comprehension tasks, which is why they are useful for translation. BART can be used to summarize articles and other lengthy texts into comprehensible outputs. BART-Large-CNN, is a fine-tuned version of BART trained to generate a summary of text after being fine-tuned on a variety of news articles. In general, encoder-decoder models can be used for both text comprehension and text generation use cases.
What is a decoder-only model?
Decoder-only models are used to decode or generate the next word or token based on a given prompt. They are only used for text generation. In terms of language generation efficiency, decoder-only models are generally more useful for pure text generation as they are simpler to train. Model series such as GPT, Mistral and LLaMa are all decoder-only. If your use case mostly requires text generation, decoder-only models are the way to go.
Note: Mistral’s 8x7B (also called Mixtral) uses a unique architecture called mixtral of experts. It’s thought that GPT-4 may be the product of a similar technique. Therefore, they do not fit easily into the decoder-only category. Furthermore, some new architecture techniques exist that do not fit into any of these categories, such as retrieval-augmented generation (RAG).
| Model series | Type |
| Mistral | Decoder-only |
| GPT | Decoder-only |
| LLaMa | Decoder-only |
| BART | Encoder-decoder |
| BERT | Encoder-only |
| Falcon | Decoder-only |
How to measure the performance quality of an LLM
There are several measurements aiming to quantify the ability of a language model to understand, interpret and accurately respond to different prompts. The methods of measuring language model performance vary based on how they are meant to be used. BERT, an encoder-only language model, is not meant for text generation purposes, so its quality would not be measured in the same way as GPT-3, a decoder-only model. Here, we will explain some of the methods used to evaluate text generation LLMs.

Measuring the quality of an LLM using academic exams
A common way to measure the quality of a generative language model is by giving it an exam. For instance, GPT-4’s performance was measured against GPT-3.5’s using a variety of academic tests. In essence, the model is subjected to a variety of exams and then compared to both human and previous model scores. It’s an effective way of evaluating a model’s reasoning abilities in an academic setting. Here is a small list of some of the exams that GPT-4 was subjected to and its scores compared to GPT-3.5 and the average human:
| Exam | GPT-4 scoring | GPT-3.5 scoring | Average human scores |
| LSAT | 163 | 149 | 152 |
| SAT | 1,410 | 1,260 | 1,028 |
| AP US History | 5 | 4 | 2.52 |
A similar performance metric to academic examination would be to give the model various Question and Answer (QnA) datasets. This is the method used in the Hugging Face Open LLM Leaderboard: a useful list which compares various LLMs based on QnA datasets. These allow for a simple way to benchmark an LLM by evaluating its general intelligence and logical abilities. Here are short descriptions of the most prominent evaluation datasets.
AI2 Reasoning Challenge (ARC)
The ARC dataset contains “7,787 natural science questions” that are characterized as having “varying levels of difficulty” and are “measurable, motivating, and ambitious”. In essence, they contain questions sourced from academia, ranging from the 3rd to 9th grade level. Here are three examples sourced from its research paper (titled: Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge):
- Which property of a mineral can be determined by just looking at it? (A) luster (B) mass (C) weight (D) hardness
- Which element makes up most of the air we breathe? (A) carbon (B) nitrogen (C) oxygen (D) argon
- What is the first step of the process in the formation of sedimentary rocks? (A) erosion (B) deposition (C) compaction (D) cementation
Massive Multitask Language Understanding (MMLU)
MMLU is a 57 task multiple-choice dataset with 15,908 questions from “various branches of knowledge” spanning the “humanities, social sciences, hard sciences and other areas that are important for some people to learn”. It has difficulty grades ranging from “Elementary”, “High School”, “College” and “Professional”, surpassing, therefore, the scope of ARC’s questions. It is used primarily to test a model’s factual knowledge. Here are 2 examples taken from its research paper (titled: Measuring Massive Multitask Language Understanding):
- One of the reasons that the government discourages and regulates monopolies is that
- producer surplus is lost and consumer surplus is gained.
- monopoly prices ensure productive efficiency but cost society allocative efficiency.
- monopoly firms do not engage in significant research and development.
- consumer surplus is lost with higher prices and lower levels of input.
- When you drop a ball from rest it accelerates downward at 9.8 m/s2. If you instead throw it downward assuming no air resistance its acceleration immediately after leaving your hand is
- 9.8 m/s2.
- more than 9.8 m/s2.
- less than 9.8 m/s2.
- cannot say unless speed of throw is given.
WinoGrande
WinoGrande is a dataset used to measure a language model’s common sense reasoning ability, differing, therefore, from MMLU and ARC which are more academically oriented. It is a dataset of 44,000 “pronoun resolution problems”, meaning that the model is judged on its ability to detect the object or person behind a pronoun based on logical clues in a sentence.
Here are a couple examples of the type of problem WinoGrande’s are based on, sourced from its research paper (titled: WinoGrande: An Adversarial Winograd Schema Challenge at Scale):
- The trophy doesn’t fit into the brown suitcase because <it’s> too large..
- Trophy
- Suitcase
- The trophy doesn’t fit into the brown suitcase but <it’s> too large..
- Trophy
- Suitcase
- Ann asked Mary what time the library closes, because <she>
had forgotten. - Ann
- Mary
- Ann asked Mary what time the library closes, but <she>
had forgotten, - Ann
- Mary
These three benchmarks—ARC, MMLU and WinoGrande—are useful for measuring a model’s general state of intelligence, factual knowledge and reasoning ability. These metrics are important when considering which LLM to use or fine-tune. In general, you would want the LLM with the lowest size or cost (in terms of number of parameters) and the highest benchmark scores (ARC, MMLU, WinoGrande, etc).
Few-shot vs zero-shot vs one-shot prompting with LLMs
Before showing the performance results, we need to explain the different ways LLMs are prompted questions. In general, there are three different types of prompting when performing QnA benchmarks: zero-shot, few-shot and one-shot prompting.
- Few-shot or k-shot is a type of prompting where the model is given some question/answer pairs that provide it with some context before asking it to answer a question.
- One-shot is a type of prompting where the model is given a single contextual question/answer pair. This method has been described in the paper Language Models are Few-Shot Learners as, depending on the task, matching “the way in which some tasks are communicated to humans”.
- Zero-shot is a type of prompting where the model is given no contextual question/answer pairs before asking a question. Zero-shot prompting is harder for a model than one-shot or few-shot due to the lack of context.
Quality comparison table between LLMs
Note: Keep in mind that comparing a 0-shot score to a 25-shot score is useless. In general, you want to keep the type of prompting the same for quality comparisons. Furthermore, comparing two data points with the same prompting method may still be inaccurate due to different testing procedures. However, the following should give a rough comparison of quality:
| Model | ARC-challenging score in % correct | MMLU score (5-shot) in % correct | WinoGrande score in % correct |
| Mistral 7B | 60.0 (25-shot), 55.5 (0-shot) | 60.1 | 78.4 (5-shot), 75.3 (0-shot) |
| LLaMa 2 7B | 43.2 (0-shot) | 44.4 | 69.5 (0-shot) |
| LLaMa 2 13B | 48.8 (0-shot) | 55.6 | 72.9 (0-shot) |
| GPT-4 | 96.3 (25-shot) | 86.4 | 87.5 (5-shot) |
| GPT-3 6.7B | 41.4 (0-shot) | 24.9 | 64.5 (0-shot) |
| Falcon 7B | 47.9 (25-shot) | 27.8 | 72.4 (5-shot) |
| GPT-2 1.5B | 30.3 (25-shot) | 26.5 | 58.3 (5-shot) |
| Mistral 8x7B | 66.0 (25-shot), 59.7 (0-shot) | 71.8 | 81.9 (5-shot), 77.2 (0-shot) |
What is the best current LLM to use as a chatbot?
Analyzing this table, keeping in mind some of the disclaimers I mentioned above, the best LLM in terms of overall quality is clearly GPT-4. However, for the best bang for your buck, go for the Mistral models. The 8x7B Mistral version uses a unique technique which combines several Mistral 7b models to produce higher quality results, creating a very efficient model that also performs well on benchmarks.
How training data can affect LLMs
The various training datasets that are used to train or fine-tune a particular model also raise important considerations. What kind of data was used? Is the dataset only useful for certain applications? Does it have any underlying biases that could influence the model?
How model biases emerge, taking BERT as an example
For most LLMs, training data is generally very broad and it is used to give the model a grasp of the basics of a language. BERT was pre-trained using Wikipedia (2,500M words) and BookCorpus (800M words). In many instances, such as with Mistral’s models, the training dataset is not to this date publicly available.
Analyzing these datasets is a good way to potentially predict the biases inherent to the model. Let’s take a look at BERT, which heavily relies upon the English Wikipedia dataset in its training. Wikipedia is often touted as a neutral and unbiased source of information – however, this might not be the case. For instance, according to an article by The Guardian, only 16% of Wikipedia editors are female and only 17% of articles for notable people are women. Furthermore, only 16% of content written for sub-Saharan Africa is written by people from that region. BERT, being pre-trained on English Wikipedia, could be expected to have inherited potential biases present in Wikipedia. There is evidence that this may be the case. BERT has been shown to have gender and racial biases in its results. So, in short, the biases in the training datasets for pre-trained models may have an impact on their text generation. It’s important to consider such biases, as they have an impact on the end user.
What is a fine-tuned model?
Fine-tuning is a process in which an already trained model is retrained on new data. Many models have offshoot models that have been fine-tuned for a specific purpose. Again, the data that has been used to fine-tune a certain model is important when considering its use-cases. Looking at BERT, one of its offshoots is FinBERT, which has been fine-tuned on a large financial language dataset. FinBERT is only useful for analyzing the financial sentiment of a sentence. If you want to read more about fine-tuning, read our article about when you should fine-tune or our article about how to fine-tune Falcon.
Some models are released with the specific goal of allowing further fine-tuning, while others have already been fine-tuned to meet a specific purpose. For instance, many models, such as Falcon, have an associated chat version which has been refined to work as a chatbot. There are several methods used to fine-tune models, but these techniques are outside the scope of this article. For general purposes, a fine-tuned model will give a description of its purposes and what fine-tuning techniques were used.
What dataset does each language model use?
Seeing how important training data is to a model’s overall performance, various web scraping methods have been developed in order to obtain quality data. For Example, Webtext, developed by OpenAI, scrapes “all outbound links from Reddit which received at least 3 karma.” Here is a list of datasets used by the most prominent models to date, keeping in mind that many developers do not share the datasets they used.
| Model or model series | Dataset |
| Mistral | Unknown |
| GPT-4 | Unknown |
| GPT-3 | CommonCrawl(filtered), WebText2, Books1, Books2, Wikipedia |
| GPT-2 | BookCorpus and Webtext |
| LLaMa 2 | Unknown |
| BERT | English Wikipedia and BookCorpus |
| Falcon | Refined Web (enhanced) |
Note: Recently, due to the highly competitive nature of LLMs, the importance of training for the final quality of a model, and potential liability issues with the data, some training data is kept secret.
The licensing and availability of LLMs
If you want to use LLMs for commercial purposes, you need to consider the license of a particular model. Furthermore, availability is not always straightforward: some models are closed source, meaning that the only way to access them is through their API.
What is a closed source language model?
A closed source model means that its source code is not available to the public. Most closed source models, such as GPT-3 and GPT-4, can only be accessed via an API. However, while running via an API can be simple, it comes at a cost. In general, if you opt to integrate an LLM into your platform, depending on the scale, it is more cost-effective to use an open source language model and train or deploy it using a platform like UbiOps.
What is an open source LLM?
An open source model means that it is publicly available and, depending on the license, can be used for commercial purposes. In addition, depending on the license, it can be fine-tuned, forked or modified in any way. In general, if you want to integrate an LLM into your platform or fine-tune a model, open source is the way to go.
Furthermore, using open source technologies is helpful for developing the LLM field, as it creates an incentive to improve and customize the models, leading to improvements for everyone in the field.
Commercial licenses
A model with a commercial license can be used for business purposes, meaning that you can integrate it into your commercial platform.
| Model or model series | License | Usable for commercial purposes? | Can it be adapted? |
| Mistral | apache-2.0 | Yes | Yes |
| GPT-4 | Closed source | ||
| GPT-3 | Closed source | ||
| GPT-2 | MIT | Yes | Yes |
| LLaMa 2 | Custom LLaMa 2 license | Yes | Yes with some extra conditions |
| BART | apache-2.0 | Yes | Yes |
| BERT | apache-2.0 | Yes | Yes |
| Falcon | apache-2.0 | Yes | Yes |
| Falcon-180B | Custom Falcon License | Yes | Yes with some extra conditions |
Overview of LLMs and their licenses.
Conclusion
While choosing an LLM that matches your needs can be a daunting task, you can narrow down your scope by comparing a model’s core characteristics against your needs: size, type, quality benchmarks, training procedures and biases, and licensing. These are just a start, of course, as there is much more that can be analyzed, but this article should provide you with an understanding of how to assess a newly released AI model, decide whether it may potentially match your requirements and if you should further investigate it.




