In this article, we will be creating a chatbot which is fine-tuned on custom documentation. We’ll use UbiOps—which is an AI deployment, serving and management platform—to fine-tune and deploy the instruction-tuned Mistral-7B model taken from Hugging Face. We’ll explain some of the methods used to fine-tune models, such as instruction tuning and domain adaptation, but also some optimization techniques which are a part of the broader field of parameter-efficient fine-tuning (PEFT). We’ll also show how we processed our documentation in order to make it usable for fine-tuning purposes.
What is fine-tuning?
Fine-tuning is a process in which a pre-trained model is re-trained on custom or specific data. A good example of a fine-tuned model is the instruct version of Mistral-7B, which is designed to be a conversational AI, i.e., a chatbot.
Fine-tuning can be done to simply change a model’s responses using instruction datasets, such as with the instruct versions of Mistral, or to create a more industry-specific model. In this guide we will be creating a UbiOps-specific model which can answer questions about our product.
Two types of fine-tuning
Lets now discuss the two types of fine-tuning relevant to this article: instruction tuning and domain adaptation. These fall into the category of supervised learning.
Instruction tuning
Instruction tuning is a type of fine-tuning in which large language models (LLMs) are judged on their ability to respond to different types of prompts. These prompts are generally in the form of a question, and instruction datasets contain an ideal completion. In our case, the Mistral-7b-instruct-v0.2 is an instruction tuned version of Mistral 7B. MistralAI has not released publicly the specific instruction dataset it used, however, they have stated that they used public instruction datasets available on Hugging Face. Let’s take a standard instruction dataset as an example to understand how instruction tuning works: The HuggingFaceH4 instruction-dataset.
Here is a sample of some of its instructions and ideal completions:
| Prompt | Completion |
| Arianna has 12 chocolates more than Danny. Danny has 6 chocolates more than Robbie. Arianna has twice as many chocolates as Robbie has. How many chocolates does Danny have? | Denote the number of chocolates each person has by the letter of their first name. We know that A = D + 12 D = R + 6 A = 2 * R Thus, A = (R + 6) + 12 = R + 18 Since also A = 2 * R, this means 2 * R = R + 18 Hence R = 18 Hence D = 18 + 6 = 24 |
| Identify the programming language used to write the given code. Input: if (20 > 18) { printf(“20 is greater than 18”); } | C |
| Write what the pronunciation of the given word sounds like. Follow the “Google pronunciation dictionary” scheme for phonetic spelling. Input: interpretations | in·tr·pruh·tay·shnz |
As we can see, we have 3 prompt/completion pairs. Instruction tuning involves feeding the LLM these pairs and adjusting its weights and biases based on how close the LLM’s prompt was to the desired completion.
Domain adaptation
Domain Adaptation is a fine tuning method that is similar to the initial training process. In general, when done in the fine-tuning stage, you will be feeding it a custom or industry-specific textual dataset. In our case, we will be feeding it the UbiOps technical documentation.
The goal of domain adaptation is to train a model to become knowledgeable in a new field or domain. There are several different ways to do this. However, in its simplest form, you give the model large textual datasets and tune it to predict the next word/token and adjust based on how far off it was in its prediction.
What is parameter-efficient fine-tuning?
PEFT is a method which is designed to reduce the computational requirements of fine-tuning. With the emergence of LLMs, often having parameters numbering in the tens of billions, having to fine-tune the entire model is expensive. PEFT allows you to fine-tune a smaller set of external parameters. As detailed in LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models, PEFT allows you to “capitalize on the remarkable capabilities of backbone models without requiring extensive computational resources.”
There are several different methods and techniques used to perform PEFT. In our case, we performed a low-ranked adaptation (LoRA).
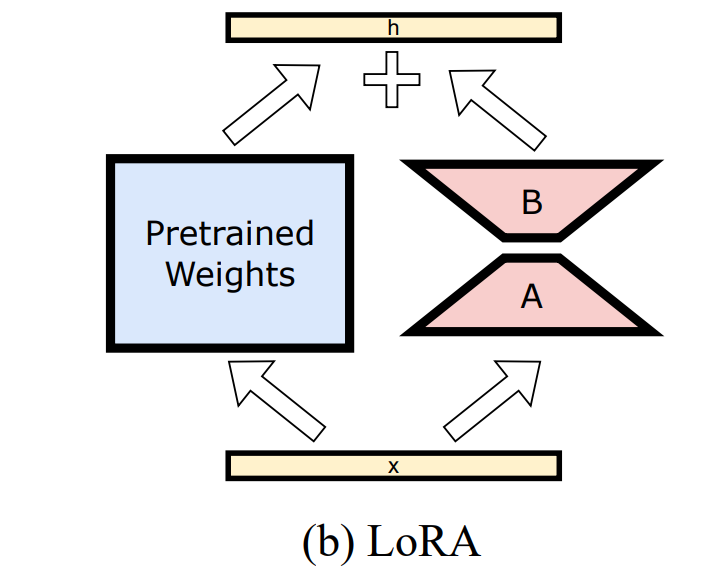
LoRA diagram, source: LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models
As shown in the figure above, LoRA “introduces a simple approach to update the parameters of a weight matrix by decomposing it into a product of two low-rank matrices.” This enables you to fine-tune a model faster, as you need to modify a smaller amount of parameters. The two low-rank matrices are the only parameters you will adjust. The output is then combined with the pre-trained matrix, which in our case would be from the Mistral-7b-instruct-v0.2 model. LoRA allows you to use far less computational power as all you need to train are the low-rank matrices.
NOTE: Issues may arise if you perform domain adaptation after instruction tuning. The LLM could “forget” that it’s supposed to be a chatbot and resort to auto-completion. However, we have not encountered any of these issues when performing this experiment. This is because our technical documentation is not very large, numbering around 11 thousand.
Why should you fine-tune a model?
Fine-tuning a model can be extremely useful. Here are two reasons why fine-tuning is important:
Firstly, fine-tuning is far less memory and computationally intensive than training a model from scratch, especially using techniques such as LoRA. This fact was detailed in a Harvard Business Review article published in July 2023.
Secondly, fine-tuning can help create a model specific to your needs. In this article, we will be demonstrating a fine-tuned version of Mistral which can answer detailed questions about UbiOps. If you want to download the code and test it immediately, see the Appendix.
How to fine-tune a model?
In our fine-tuning demonstration, we will be using the PEFT library from HuggingFace as well as the UbiOps API. For the training data, we will be using the UbiOps technical documentation.
Choose a base model
As mentioned, our base model is the Mistral-7B-Instruct-v0.2 model which we will retrieve from Hugging Face.
Create the training data
The next step is to create the training data. As mentioned earlier, we will be fine-tuning the Mistral-7b-instruct-v0.2 model using the UbiOps public documentation. These files, when downloaded, are written in markdown and need to be preprocessed in order to tokenize and feed them correctly to the model. The langchain python library has a method named MarkdownHeaderTextSplitter. We will also be using langchain’s TokenTextSplitter to split the paragraphs into 256 words. You can use any size limit you want but it is dependent on the size of the GPU’s VRAM. We will be using this to split the text into paragraphs:




