Exciting things you can build with the new UbiOps operators!
In our first blog on pipeline operators, we used them to speed up a video processing pipeline. Specifically, we used the create subrequests and the collect subrequests operators to analyze multiple frames of the video simultaneously, by introducing parallelization. This time we will highlight three other operators. We will use the conditional logic operator, the function operator and the raise error operator. Using these operators we will implement testing, separate our model from our post processing steps, and conditionally route the results of our model to either one of two postprocessing steps.
The example use case: testing and conditional postprocessing
In this blog post, we are going to predict the weight of a fish. The model that we use is a Regression model that predicts the weight of a fish (in grams), from its length and height (in centimeters). The model is trained on the fish market dataset.
Let us assume that we want to show the results of our prediction service directly to our end-users. Consequently, we want nice formatting of our results. We decide that we want our pipeline to return results in grams if the predicted weight of the fish is below one thousand grams, and have them expressed in kilograms if the fish’s predicted weight is at least one kilogram.
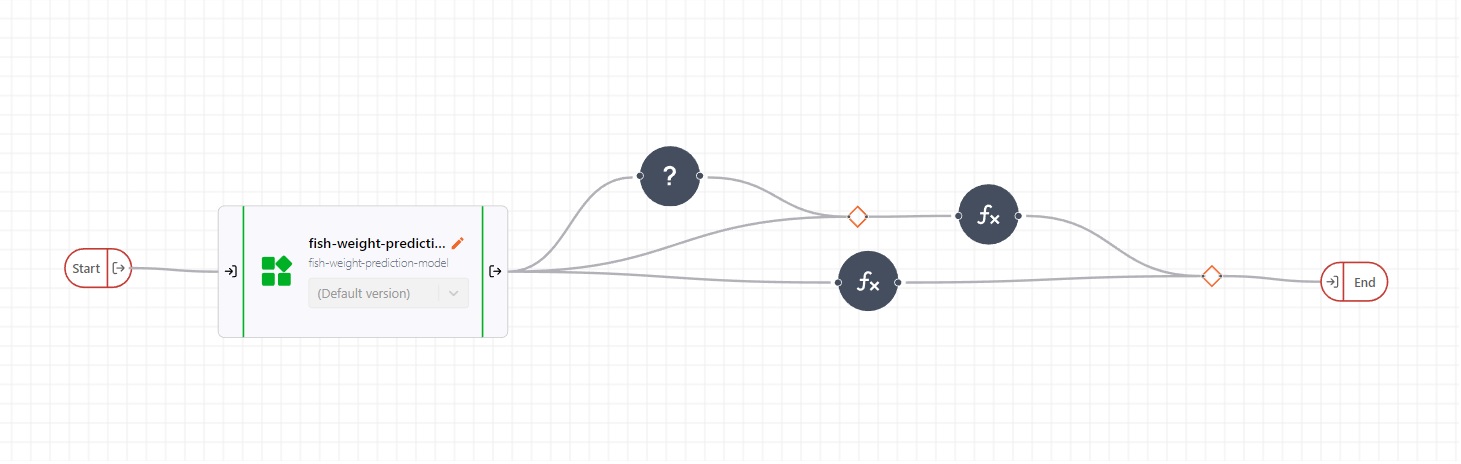
As a last requirement, we need to take into account that our model is only valid in the regime where both the height and the width of the fish are at least three centimeters. In this case, we want to raise an error in the case that either of these parameters measured are below these thresholds. This leaves us with three different paths that we need to consider. The paths are visualised in the flowchart below:

We will work out each of the three paths separately and combine all three into our final pipeline. Let us first define the specs of the deployment that stores our model.
Our deployment
We use only one deployment, whose function is to pass the input fields to our prediction model, and to return the prediction and the unit in which the prediction is expressed. This is grams (“g”) by default. The deployment has the following configuration
| Name | Value |
| Name | fish-weight-prediction-model |
| Description | A Regression model that predicts the weight of a fish from its height and width |
| Input field | Name: height_cm, data_type: double Name: width_cm, data_type: double |
| Output field: | Name: predicted_weight, data_type: double Name: unit, data_type: string |
Our deployment code is shown below. Additionally, we have added a file named ‘fish_weight_prediction_model.h5’ and a ‘requirements.txt’ to our deployment package. The prior file contains our model artifcact. The latter ensures the installation of joblib and scikit-learn.
import joblib
class Deployment():
def __init__(self):
filename = 'fish_weight_prediction_model'
self.loaded_model = joblib.load(filename)
def request(self, data):
x1 = data["height_cm"]
x2 = data["width_cm"]
result = self.loaded_model.predict([[x1, x2]])[0][0]
return {"weight_predicted": result,
"unit": "g" }Path 1: Testing for the range of our model
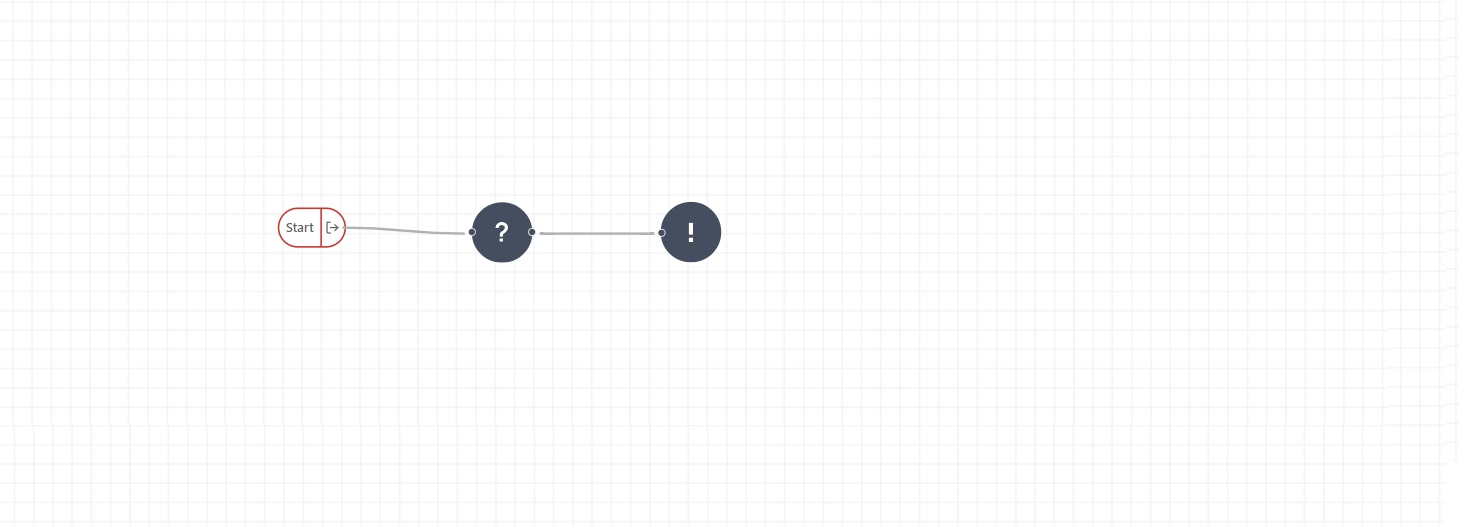
The range in which our model holds, is when both the height and the width of the fish are more than three centimeters. To implement this unit testing, we connect the start of our pipeline immediately to a conditional logic operator. To this operator, we add two input fields,height_cm and width_cm, and the following expression:
height_cm < 3 or width_cm < 3
The next step in the pipeline is triggered when this expression is ‘true’. For example when the width of the fish is 2.9cm. In this set-up, the next step in our pipeline will be the raise error operator. Let’s add the following error message: ‘The input values are out of range for this model!’. This message will be returned to the user that inserted the out-of-range input values.
Path 2: Conditional post-processing route 1
If the predicted weight of the fish is less than 1000g, we want to express our final answer as a number that is rounded to the nearest gram. We connect our model to the start of our pipeline, and add a subsequent conditional logic operator that checks the following expression:
weight<1000,
where weight is of datatype `double precision`.
Next step, we add a function operator that rounds the predicted weight to full milligrams. We use the following expression:
“%.0f” % weight
Note that the conditional logic operator only determines if the next step of the pipeline is run. It does not pass variables itself. Therefore, to be able to process the prediction from the model, we need to connect both the conditional logic operator and the output from the deployment to the function operator.
Lastly, we connect both the output from the function operator (‘weight’) and the data field ‘unit’ (which is “g” by default) from our model to the output of our pipeline.
Our final set-up for this post-processing step then looks as follows:

Path 3: Conditional post-processing route 2
Our third and last path should be executed when the predicted weight of the fish exceeds 1000 g. As in path 2, we add a conditional logic operator after our model and have it test for the condition:
weight >= 1000,
With again the datatype of ‘weight’ and the output of the operator as ‘Double precision’.
In case that this condition hold, we apply the function:
“%.0f” % (weight/1000)
to the prediction of our model. We connect all operators in a similar fashion as we did in Path 2, with one addition. Because we need to convert the unit of our prediction, we add another function operator to our pipeline, and connect it to the field ‘unit’ of our model. We process this field using the following expression:
“kg” if unit == “g” else None
This expression ensures that the unit of our prediction is changed into ‘kg’, if this path is pursued.
Our final set-up for this path looks as follows:
Bringing everything together
Finally, we add all three paths to our pipeline, so that we end up with the following solution:

Using the pipeline
That’s it! We have now created a pipeline that processes its input in either of three ways. You can verify the effect of the conditional nature of the pipeline, by e.g. trying out: (height_cm, width_cm) = (2, 3), (5, 4), (20, 30).


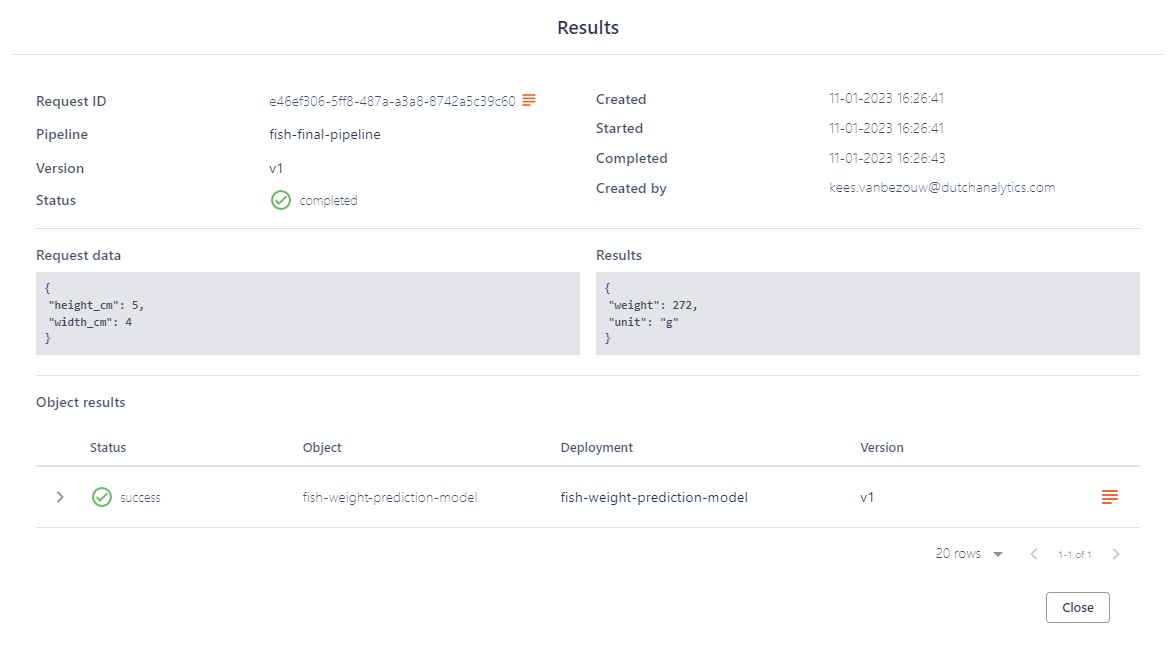
We have decoupled the postprocessing steps from our model, so that we can easily change our postprocessing steps without requiring to change new deployment code. This also allows us to use the UbiOps monitoring facilities to monitor the results of our model, independent of the involved postprocessing steps. It can be helpful if the same model is used in different pipelines, or if you want to track the results of the model over a longer period of time, while the postprocessing is still up to change.
As a next step, you can control the chosen post processing step by adding an input parameter to your pipeline input, that determines which post processing step to perform.
To allow for more complex types of conditional post processing, you could swap the function operators for your own custom deployments.
Did you manage to reproduce the same pipeline? Do you have an idea that you want to deploy with pipeline operators yourself? Always feel free to reach out via our support channels!




