Training on UbiOps¶
The UbiOps Training Functionality can be used to train Machine Learning models. The functionality is characterized by a fast iteration cycle, allowing a user to quickly try out different training scripts and configurations. The training functionality is built on two concepts:
- Experiments: which define the training set up that you will use for your training code.
- Training runs: which run inside the experiments. They are the actual code executions on a specific dataset.
Training runs can be compared on the basis of output metrics. Also, a native integration with the File Storage system ensures that input training scripts, output model artifacts and other output files can be stored for later (re)usage.
Training can be enabled in your project by navigating to the Training page and clicking enable training. If enabled UbiOps will prepare a training set-up in your project, in the form an immutable deployment called training-base-deployment. This deployment is used to run training experiments and runs in the background.
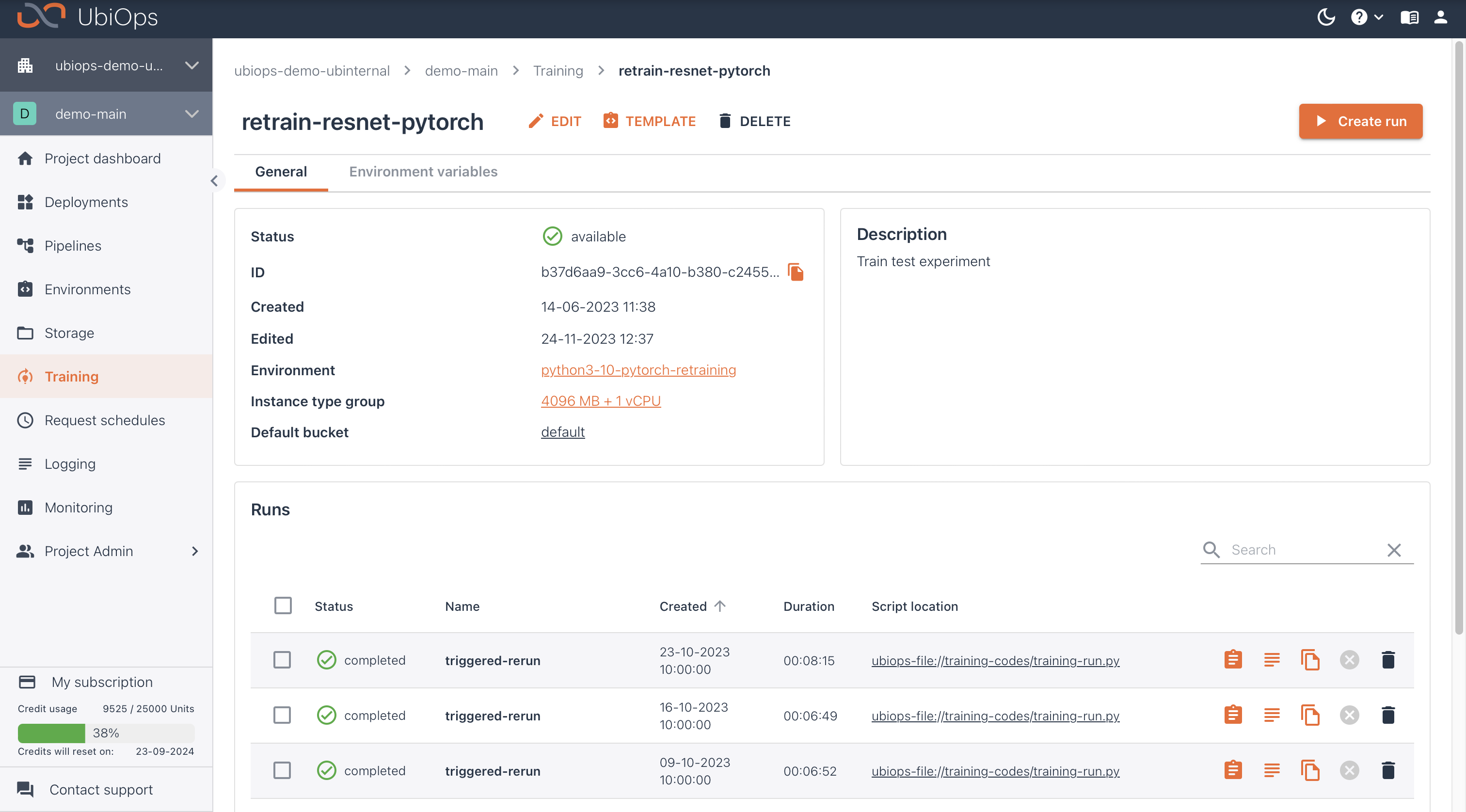
If you want to train your model you first need to create an experiment. Experiments define, among other things, the environment your training code will run in and what instance type (group) will be used. After creating an experiment you can initiate training runs. These training runs are the executions of your training code on a specific dataset.
Experiments¶
Experiments define the training set-up that you will use, such as the environment it should run in, what it should be called, and what instance type (group) you would like to use. Runs belong to experiments, and they are the actual training jobs. Runs thus specify what code is run, on what data, and with what parameters. Since runs all share the same environment specified by the experiment, runs can be used for techniques like hyperparameter tuning. If you want to compare training implementations with different frameworks (i.e. scikit-learn versus TensorFlow), you will need separate experiments for this.
You can create experiments through the WebApp and the Python Client Library. The workflows are the same for both. As with deployments, it is possible to add experiments as an object to a pipeline or to schedule training runs with a request schedule.
When creating a new experiment you can configure the following settings:
- Name: the name of your experiment
- Description: a description for your experiment
- Instance Type (group): what instance type (group) to use for all your runs. This is where you can specify what GPU to use as well.
- Environment: what code environment to run in, this includes what Python version and any dependencies that you need for your runs.
- Default bucket: the default bucket to use for any outputted files created by your training run.
- Environment variables: environment variables that you can use in your training code via
os.environ--Scaling & data retention: these settings dictate how many runs can be handled in parallel at a time and for how long your run information is saved after a training run has been created. - Labels: key:value pair labels that can help you categorize your experiments
These settings work the same as they do for Deployment versions.
If you want to create a new environment to use in your experiment, see environments.
Below you can see a code example of creating a training run with the Python Client Library.
import ubiops
training = ubiops.Training()
project_name = 'project_name_example' # str
experiment_name = 'experiment_name_example' # str
# Create experiment
api_response = training.experiments_create(
project_name=project_name,
data=ubiops.ExperimentCreate(
name=experiment_name,
instance_type_group_name='4096 MB + 1 vCPU',
description='A training experiment',
environment_name='python3-10',
default_bucket='default',
labels={"type": "pytorch"}
)
)
print(api_response)
# Close the connection
training.api_client.close()
If you want to use a custom environment in your training experiment you can use the code snippet below to create it.
import ubiops
configuration = ubiops.Configuration()
# Configure API token authorization
configuration.api_key['Authorization'] = "Token <YOUR_API_TOKEN>"
api_client = ubiops.ApiClient(configuration)
core_api = ubiops.CoreApi(api_client)
project_name = 'project_name_example' # str
experiment_name = 'experiment_name_example' # str
data = ubiops.EnvironmentCreate(
name=experiment_name,
base_environment='python3-10'
)
# Create environment
api_response = core_api.environments_create(project_name=project_name, data=data)
print(api_response)
# Close the connection
api_client.close()
Training runs¶
For every experiment, you can create multiple training runs. These runs are the actual code executions on a specific dataset. When creating a new training run you can configure the following settings:
- Name: the name of your run
- Description: a description for your run
- Training code: the training code that actually needs to be run. This can be in the form of a single Python file or a zip containing at least a
train.pyand any other required files. - Training data: a file containing the training data for your run.
- Parameters: any parameters you want to use in your training code. This can be any dictionary and can also be left empty.
Upon initiating this training run, you can also configure a timeout:
- Timeout: a timeout after which the run will automatically be stopped. This can be used to avoid running for hours on expensive hardware when this wasn't expected.
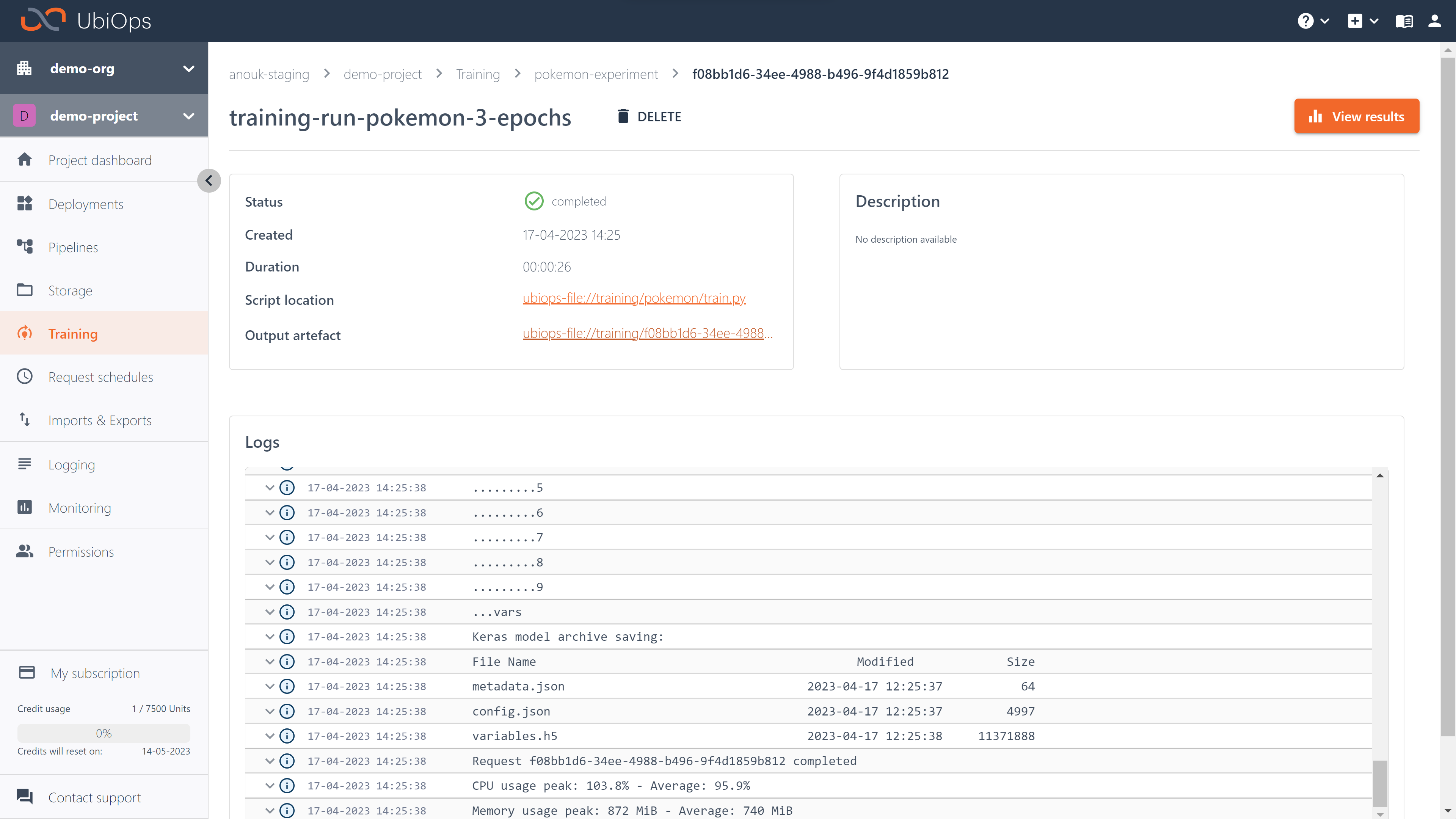
Below you can see a code example of creating a training run with the client library.
import ubiops
configuration = ubiops.Configuration()
# Configure API token authorization
configuration.api_key['Authorization'] = "Token <YOUR_API_TOKEN>"
api_client = ubiops.ApiClient(configuration)
training_instance = ubiops.Training(api_client)
project_name = 'project_name_example' # str
experiment_name = 'experiment_name_example' # str
run_name = 'run_name_example' # str
new_run = training_instance.experiment_runs_create(
project_name=project_name,
experiment_name=experiment_name,
data=ubiops.ExperimentRunCreate(
name=run_name,
description='Some description',
training_code='./path/to/train.py',
training_data='ubiops-file://default/training_data.zip',
parameters={
'nr_epochs': 15, # Example parameters
'batch_size': 32
}
),
timeout=14400
)
You can also create multiple runs using a list of parameters, which is useful for hyperparameter tuning. You can do this in two steps:
First define the parameters:
run_parameters = [
{
"n_estimators": 100,
"learning_rate": 0.08,
"subsample": 0.5
},
{
"n_estimators": 150,
"learning_rate": 0.12,
"subsample": 0.75
}
]
for i, run_parameters in enumerate(parameter_sets):
run_template = ubiops.ExperimentRunCreate(
name=f"run-{i}-estimators-{parameter_sets['n_estimators']}-learning_rate-{parameter_sets['learning_rate']}",
description= f"Parameter sweep run {i}" ,
training_code= RUN_SCRIPT, # A reference to a location containing the training code. Can be an UbiOps file uri, directory or file
training_data= training_data, # A reference to a location containing the training data. Can be an UbiOps file uri, directory or file
parameters= run_parameters # Dictionary containing key/value pairs with training parameters
)
training_instance.experiment_runs_create(
project_name=PROJECT_NAME,
experiment_name=EXPERIMENT_NAME,
data= run_template,
timeout=14400
)
Note: Training runs are only saved for the maximum request retention time allowed by your subscription, you can contact our sales department if you need a longer retention time.
UbiOps will automatically scale the necessary compute resource in the background. When idle, the number of active instances of an experiment will scale to zero. A maximum of five training jobs can run in parallel on different instances, as the default maximum instances for training is set to five. You can change the maximum instances upon request or by using the API, it is not possible to change the number of maximum instances in the WebApp. The number of maximum concurrent training runs can also be limited by subscription (resource) limits.
Training code format¶
The training code that you can use in your runs needs to fulfil the following criteria:
- The training file needs to contain a function called
train(training_data, parameters, context, base_directory)that returns a dictionary containing the following fields:artifact,metadata,metrics,additional_output_files. All in- and output parameters are optional. - The artifact entry of the returned dictionary cannot be null, the other fields in the dictionary can be left empty if you don't need them.
The training code can be passed in the following formats:
- a zip file containing a
train.pyand any other files you might want to use in your code. These files can include Python files that are referenced in yourtrain.py. - a zip file containing a
training_packagedirectory with atrain.pyand any other files within it - a single Python source file that can have any name
The training_data argument passed to your train function is a file path to the training data file. The parameters argument is a dictionary containing any additional parameters passed to the training code. If, for example, you want to be able to vary the batch size used in your code with every training run, it would make sense to pass that in the parameter dictionary and read the value from there, rather than hard-coding it. The context parameter contains additional metadata, identical to request to deployment versions. Lastly, the base_directory is the absolute path to the directory of the training code.
The context dictionary contains the following keys:
| The training run context dictionary | |
|---|---|
| Key (type) | Description of the value |
| id (str) | Unique identifier for the training run |
| user_id (str) | Unique identifier for the initiator of the training run |
| request mode (str) | Mode of the request, defaults to batch for training runs |
| name | Name of the training run |
| project (str) | Name of the project that hosts the experiment |
| experiment (str) | Name of the experiment |
| experiment_id (str) | Unique identifier of the experiment |
The fields in the returned dictionary should have the following data types:
- artifact:
file - metadata:
dictionary - metrics:
dictionary - additional_output_files:
array of files
This means that there are no predefined metrics for you to use. You can define your own metrics in your training run and return them in the metrics dictionary with a name and a value.
Below you can find an example training code that trains a scikit learn KNN classifier. It expects a parameter called test_size that influences the train test split.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from joblib import dump
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
def train(training_data, parameters, context):
print("Loading data")
sample_data = pd.read_csv(training_data)
X = sample_data.drop(["Outcome"], axis = 1)
y = sample_data.Outcome
# Split data into train and test set
test_size = parameters["test_size"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=42, stratify=y)
# Set up a knn classifier with k neighbors
knn = KNeighborsClassifier(n_neighbors=7)
# Fit the model on training data
knn.fit(X_train,y_train)
# Get accuracy on test set. Note: In case of classification algorithms score method represents accuracy.
accuracy = knn.score(X_test, y_test)
print('KNN accuracy: ' + str(accuracy))
# Let us get the predictions using the classifier we trained above
y_pred = knn.predict(X_test)
# Output classification report
print('Classification report:')
print(classification_report(y_test, y_pred))
# Persisting the model artifact
dump(knn, 'knn.joblib')
return {
"artifact": "knn.joblib",
"metadata": {},
"metrics": {"accuracy": accuracy},
"additional_output_files": []
}
Passing training data to your run¶
Training data needs to be passed to your training run in the form of a UbiOps file. This means that you are currently limited to using single files, for instance zipped datasets, as training data. If you would rather read directly from your own S3 bucket or if your data is not stored as a file but rather in a relational database, you can leave the training_data field empty and simply read in the data directly in your code. In this last scenario it's important to pass any required credentials as a secret environment variable to your experiment, to avoid hard-coding credentials.
We provide multiple how-to's and tutorials that explain how you can use the training functionality and give examples.