Work with the create-subrequests operator¶
UbiOps pipelines come with some predefined operators that you can use. One of those operators is the create-subrequests operator. Read on to find out how you can work with it.
Configuring the create-subrequests operator¶
Once you have added the create-subrequests operator to your pipeline canvas, the UI will prompt you to provide the following:
- A source object
- The batch size (advanced setting)
If you want to add this operator using the Client Library you need to provide the following parameters:
| Field | Description |
|---|---|
| name | one-to-many |
| reference name | one-to-many |
| reference type | operator |
| configuration (example) | { "batch_size": null, }# Input fields should be the same as the output fields of the source object "input_fields": [{"name": "output", "data_type": "double"}], # Input fields and output fields should be the same "output_fields": [{"name": "output", "data_type": "double"}] |
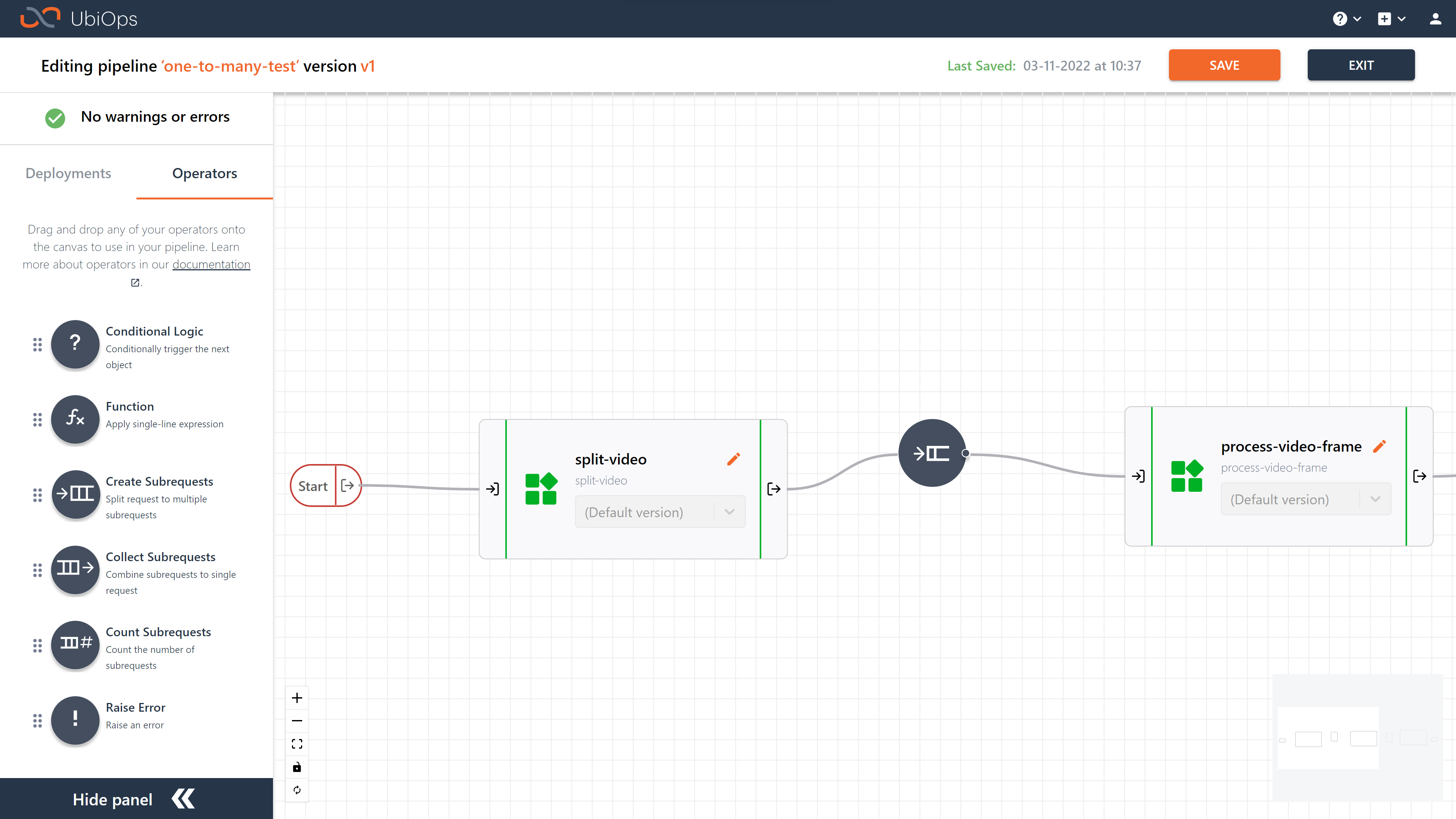
The source object is the object whose output you want to split into subrequests for the next object. Let's say you have a video processing pipeline for instance, where you want to process each frame in parallel. In this scenario you would have a pipeline object that splits the videos into frames (video-splitter), and a pipeline object that processes a single frame (process-video-frame). To parallelize the processing of the frames you would need to add a create-subrequest operator in between these to pipeline objects. That operator would then need source object video-splitter. See the image below for the example set-up.
The batch size is a parameter that allows you to control how big the batches of subrequests should be that will be parallelized. For example, if your video is split in 500 frames, and you configure the batch size to be 100, 5 parallel requests will be created for your deployment, each containing 100 subrequests. This allows you to parallelize over 5 instances of your deployment, each instance working through 100 subrequests. If you configure batch size as none, UbiOps will optimize your batches for you and will try to split the subrequests over the maximum deployment concurrency allowed for your subscription. This will maximize parallelization with the least amount of request overhead.
Double-check your maximum number of instances
When using the create-subrequests operator, make sure that the deployment you are spreading the requests over actually has its maximum number of instances set to above 1. Otherwise, the subrequests cannot be parallelized, and they will be handled in order of creation.
Preparing your deployment code to work with the operator¶
To be able to use the create-subrequests operator with your deployment, your deployment code should return a list of outputs, as opposed to a single output. The operator will split this list into subrequests. In the case of our video processing example, our video-splitter code should thus look something like this:
class Deployment:
def __init__(self, base_directory, context):
print("Initialising My Deployment")
def request(self, data):
print("Processing request for video splitter")
video = data["video"]
# < code to split video into frames>
# In the return statement we return a list of dicts
return [{"frame": frame1}, {"frame": frame2}, {"frame": frame3}]
Our video-splitter of our example has its output defined as frame of type file. You do not need to change your output type to array for it to work.
That's all there is to this operator. If you run into any issues though, do not hesitate to contact support.